
Mile
Zero
June 19, 2022
The Many-Threaded Hydra
Iain M. Banks' classic novel Player of Games follows Jernau Morat Gurgeh, who is sent from the Culture (a socialist utopia that's the standard setting for most of Banks' genre fiction) to compete in a rival society's civil service exam, which takes the form of a complicated wargame named Azad. The game is thought by its adherents to be so complex, so subtle, that it serves as an effective mirror for the empire itself.The Emperor had set out to beat not just Gurgeh, but the whole Culture. There was no other way to describe his use of pieces, territory and cards; he had set up his whole side of the match as an Empire, the very image of Azad.
Another revelation struck Gurgeh with a force almost as great; one reading — perhaps the best — of the way he'd always played was that he played as the Culture. He'd habitually set up something like the society itself when he constructed his positions and deployed his pieces; a net, a grid of forces and relationships, without any obvious hierarchy or entrenched leadership, and initially quite peaceful.
[...] Every other player he'd competed against had unwittingly tried to adjust to this novel style in its own terms, and comprehensively failed. Nicosar was trying no such thing. He'd gone the other way, and made the board his Empire, complete and exact in every structural detail to the limits of definition the game's scale imposed.
Azad is, obviously, not real — it's a thought experiment, a clever dramatic conceit along the lines of Borges' famous 1:1 scale map. But we have our own Azad, in a way: as programmers, it's our job to create systems of rules and interactions that model a problem. Often this means we intentionally mimic real-world details in our code. And sometimes it may mean that we also echo more subtle values and viewpoints.
I started thinking about this a while back, after reading about how some people think about the influences on their coding style. I do think I have a tendency to lean into "playful" or expressive JavaScript features, but that's just a symptom of a low boredom threshold. Instead, looking back on it, what struck me most about my old repos was a habitual use of what we could charitably call "collaborative" architecture.
Take Caret, for example: while there are components that own large chunks of functionality, there's no central "manager" for the application or hierarchy of control. Instead, it's built around a pub/sub command bus, where modules coordinating through broadcasts of custom events. It's not doctrinaire about it — there's still lots of places where modules call into each other directly (probably too many, actually) — but for the most part Caret is less like a modern component tree, and more like a running conversation between equal actors.
I've been using variations on this design for a long time: the first time I remember employing it is the (now defunct) economic indicator dashboard I built for CQ, which needed to coordinate filters and views between multiple panels. But you can also see it in the NPR primary election rig, Weir's new UI, and Chalkbeat's social media card generator, among others. None of these have what what we would typically think of as a typical framework "inversion of control." I've certainly built more traditional, framework-first applications, but it's pretty obvious where my mind goes if given free rein.
(I suspect this is why I've taken so strongly to web components as a toolkit: because they provide hooks for managing their own lifecycle, as well as direct connection to the existing event system of the DOM, they already work in ways that are strongly compatible with how I naturally structure code. There's no cost of convenience for me there.)
There are good technical reasons for preferring a pub/sub architecture: it maps nicely onto the underlying browser platform, it can grow organically without having to plan out a UML diagram, and it's conceptually easy to understand (even if you don't just subclass EventTarget, you can implement the core command bus in five minutes for a new project). But I also wondered if there are non-technical reasons that I've been drawn to it — if it's part of my personal Azad/Culture strategy.
I'm also asking this in a very different environment than even ten years ago, when we used to see coyly neo-feudalist projects like Urbit gloss over their political design with a thick coat of irony. These days, the misnamed "web3" movement is explicit about its embrace of the Californian ideology: not just architecture that exists inside of capitalism, but architecture as capitalism, with predictable results. In 2022, it's not quite so kooky to say that code is cultural.
I first read Rediker and Linebaugh's The Many-Headed Hydra: Sailors, Slaves, Commoners, and the Hidden History of the Revolutionary Atlantic in college, which introduced me to the concept of hydrarchy: a type of anarchism formed by the "motley crew" of pirate ships in contrast to the strict class structures of merchant companies. Although they still had captains who issued orders, that leadership as not absolute or unaccountable, and it was common practice for pirates to put captured ship captains at the mercy of their crews as a taste of hydrarchy. A share system also meant that spoils were distributed more equally than was the case on merchant ships.
The hydrarchy was a huge influence on me politically, and it still shapes the way I manage teams and projects. But is it possible that it also influenced the ways I tend to think about and write code systems? This is a silly question, but not I think a stupid one: a little introspection can be valuable, especially if it provides insight in how to explain our work to beginners or accommodate their own subconscious worldviews.
This is not to say that, for example, Caret is an endorsement of piracy, or even a direct analog (certainly not in the way that web3 is tied to venture capitalism). But it was built the way it was because of who did the building. And its design did have cultural implications: building on top of events means that you could write a Caret plugin just by sending messages to its Chrome process, including commands for the Ace editor. The promise (not always kept, to be fair) was that your external code was using the same APIs that I used internally — that you were a collaborator with the editor itself. You had, as it were, an equal share in the outcome.
As we think about what the "next era of JavaScript" looks like, there's a tendency to express it in terms of platforms and layers. This isn't wrong! But if we're out here dreaming up new workflows empowered by edge computing, I think we can also spare a little whimsy for models beyond "pure render functions" or "strict hierarchy of control," and a little soul-searching about what those models for the next era might mean about our own mindsets.
September 21, 2021
I am FM
My last day at NPR was September 3, and I started at Chalkbeat on September 13. In the nine days in between, I tried to detox: I stayed away from the news, played a lot of Castlevania, and — in an effort to not feel completely useless — worked on a project I've been meaning to tackle for a while: I wrote a browser-based FM synth modeled on the classic Yamaha DX-7.
The DX-7 is the classic Lament Configuration of digital sound design. It's not only based on a model of synthesis that's unintuitive, but Yamaha wrapped it in a pushbutton user interface that discourages experimentation. Its sound defined an era almost entirely through the presets: the piano arpeggios from Twin Peaks, countless Whitney Houston ballads, and the bass line from Take on Me. I never owned a genuine DX-7, but I had one of Yamaha's budget models, and learning to build sounds on it was a long-standing white whale of mine.
Modulation Operations
Most synthesizers are what we call additive and subtractive. You generate a waveform, either by combining different wave shapes (sine, rectangle, sawtooth, or triangle) or using a noise generator, and then patch that through a series of filters and effects, and out the other end either emerges a transcendant reinterpretation of Bach (if you're Wendy Carlos) or a kind of deranged squawking (if you're me). This kind of synthesis isn't easy, per se, but it makes sense to someone who has used, say, a guitar pedalboard.
The DX-7 works differently, using something called frequency modulation (FM) synthesis. Essentially, it uses up to six sine wave oscillator units (called "operators"), but most of them aren't audible at any given time. Instead, the secondary units (called "modulators") are used to tweak the frequency of the audible operators ("carriers"). When the wave output of the modulator goes up, so does the frequency of its carrier. When the wave goes down, the freqency dips. Since these changes in frequency happen many times a second, and are often scaled to the input pitch from the keyboard, the result are complicated harmonic patterns, often described as metallic, bell-like, percussive.
In the original DX-7 hardware, this is all done using a polynomial math equation, effectively shifting the sample location for the carrier wave based on the modulator value (there's a useful .gif at Wikipedia illustrating the principle). You can do this with relatively cheap processors, and indeed that's how most of the JavaScript implementations still do it: they generate a stream of audio data directly from the phase math, and pipe that to an output. But for the sake of prototyping, I decided to do it a different way, using the native WebAudio processing graph.
{kind=link}
Adapting theory to practice
WebAudio is a kind of beautiful monstrosity. It's easy to imagine an API designer deciding that browser audio should be mostly WebGL-style primitives, basically just handing you an audio buffer array and leaving the sound generation up to you. Or the pendulum could have swung the other way, toward extreme user-friendliness, with just a slightly more performant version of the <audio> tag letting you load and trigger preset clips.
Instead, the final API ends up looking more akin to a classic Moog patchbay or a studio effects rack, letting you wire various modules together into a complex signal chain. Those nodes start out as simple oscillators and gain amplifiers, but from there it gets pretty batteries-included: nodes for impulse convolution, multiple shaped filters, and compression, plus a custom "script worker" node as an escape hatch.
Crucially for my purposes, WebAudio signal nodes can be wired to more than just audio inputs and outputs. You can also hook nodes into the control parameters, so that the output from one changes the volume or strength of another. In our case, we can use the audio signal from our modulators and pipe it into the frequency value of our carriers. It's not quite the same as the classic DX-7 formula, but it performs very well, and the sound actually isn't that far off. You can hear the classic EPIANO1 preset adapted to my code on the GitHub demo page for the project.
However, while this implementation felt more intuitive than juggling Math.sin(), WebAudio also has some quirks that made it tricky. For example, oscillators are single-shot: they can only be started and stopped once. The API is full of this kind of design, where you're supposed to create nodes, connect them to the graph, and then throw them away. But when you have modulator oscillators feeding into carrier oscillators in a complicated web of amplifiers and filters, disposable audio sources don't really fit the design.
In the end, I had to wrap the whole thing in a disposable Voice class that encapsulates an arrangement of operators for a single note. When the synth is asked to play a sound, it creates a Voice containing a fresh set of operators, hooks that up to the audio context, and sends it on its merry way. This effectively makes our synthesizer polyphonic by default, since each individual frequency gets its own voice on demand. It feels wasteful, but it works.
Gradual complexity
Working on a project like this makes me think a lot about how it is that I build projects, and how to teach others to do the same. We often tell junior developers that they should learn by creating something fairly complex, but we don't really tell them how to do it. I suspect this is because it becomes fairly instinctual over time, so it's hard to explain.
Part of what we don't tell junior developers is that big projects are built out of little projects, one level of abstraction at a time. For example, for the Hello Operator repo, the process of getting a (mostly) working synthesizer looks like:
- Hook up some basic oscillators and trigger them on a timer
- Wrap those oscillators in an Operator class and connect them together
- Instead of using a timer, set the keyboard to trigger playback
- Wrap the Operator objects in a Voice, so that they can be played repeatedly
- Add a MIDI keyboard and feed its input directly into the synth
- Wrap MIDI in an EventTarget so it can be used for more than just notes
- Add basic inputs that tweak the Operator settings, wired directly to MIDI
- Create a bad abstraction to marry browser UI to the operator settings across multiple parameters
- Replace that abstraction with something that handles updates regardless of source, whether from the browser UI or the knobs on the MIDI controller
I suspect that when we say "build bigger projects," what people hear is that their application needs to spring fully-formed from their head like Athena, but literally nothing I've ever built has been scoped that way. It's always been a gradual accretion of functionality. Caret, for example, started out as just a text box and a keyboard input, and everything else, from tabs to project management, grew from there.
It's not that I don't have a plan at all — I knew from the start, for example, that I'd want a solid system that encapsulated the MIDI handling code and turned it into something more JavaScript-friendly — but the point of experience is learning where to put the grotesque hacks that you'll later replace with those better systems. And you get that experience by failing to make good placeholders on your first few projects.
Did I accomplish my goal of learning to program a DX-7? No. But ultimately, for these kinds of projects, that's not really the point. I learned a lot about sound, how the browser processes it, and how to handle new kinds of input. One day, I might even finish it. Brian Eno, eat your heart out.
June 18, 2021
Upstream
In 2013, Google decided to shut down Google Reader, one of a number of boneheaded decisions that the company undertook in pursuit of some bizarre competition with Facebook. At the time, I decided to try an experiment: I'd write my own RSS reader, try it for a few months, and if it didn't work out I'd switch to one of the corporate replacement options.
Eight years later, I still use Weir to keep up with various feeds, blogs, and news updates. It's a deeply personal piece of software — the project that made me fall in love with the idea of code tools that are crafted just for a single person, like making your own workbench or sewing your own clothes.
But I also haven't substantially upgraded or altered Weir in all that time, even as I've learned a lot about developing on the web. So this week, while I had the apartment to myself, I decided to experiment again and build a new client (while mostly leaving the server alone). After I get a chance to work out any remaining kinks, I'll move it over to become the new built-in UI for the application.
I love my curvy UI
The original client was written in Angular 1 as a learning project. It's fine! It's mostly fine. The main problem that Angular had — and which other front-end frameworks have inherited — is that it wanted you to do all your work at a level of abstraction from the DOM, and any problems that couldn't be cleanly moved into the state object would get messy. Browsers were also worse in those days: no intersection observers for handling scroll positioning, inconsistent event handling, no support for easy concurrency with async/await. So there's some awkward behavior in the original client that never felt like it would be easy to fix, because it required crossing that abstraction barrier.
Unsurprisingly, for the rewrite I organized the code via web components — extended from the same base class that I used for Radio, and coordinated over a central event bus similar to the command system in Caret. The only code that translated over mostly unchanged was the sanitization module, which loads each post body into an inert document and processes it to remove ads, custom styles, class names, and anything else that isn't plain HTML content.
What is surprising is that the two codebases are not notably different in size — in fact, CLOC gives roughly the same line counts between the two. Of course, that only includes code I wrote. The original Weir client also requires 80KB of Angular runtime code, which has to be downloaded, parsed, compiled, and run before any of my code shows up onscreen. I'm using those precious first-paint seconds to indulge in a build-free workflow — all JS is just loaded as raw ES modules, and components fetch their styles and markup from individual HTML files instead of using Less and Browserify. It all evens out, but if I decide I'm tired of paying a startup penalty, it's certainly easy enough to add Rollup to the process.
Typically when I go framework-less, the thing I miss most is iteration in templates. It's still a little clumsy in the new client code. But combining Element.replaceChildren(), shadow DOM slots, and elements that act as template partials, it's honestly much less of an issue these days. I could add a databinding function to diff and transition elements, as Radio does for its sorted podcast lists, but (other than the feed management table) there's almost no part of the UI here where view data persists between state transitions, so it's not really worth the effort.
Scrolls like the Dead Sea
Instead of using a stack of full-window UI "scenes" for different tasks within the UI (such as settings, feed management, and reading stories), the new client is organized in three columns (admin, story listings, and reader). On desktop, they line up side-by-side across the window, and on mobile each one takes up the whole screen, similar to something like Tweetdeck or Mastodon. CSS scroll snap makes it easy to swipe between them horizontally or scroll vertically within the individual panels as their content requires. In practice this gives us a native-feeling, responsive UI pattern with no JavaScript, and it will feel more natural when snap stop is supported to prevent overscroll.
Desktop view: three columns in a row
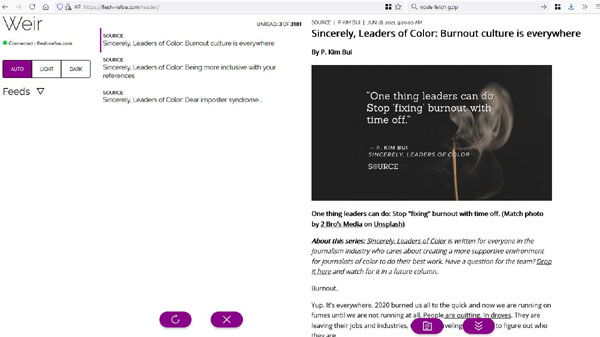
Mobile: swipeable columns (artist's rendering)

Unfortunately, creating a mobile UI that scrolls in two directions like this means that viewport management is more difficult to handle programmatically. For example, when loading a story into the reader panel, we want to scroll smoothly over to that column from the story list, while immediately jumping within the reader content to the top of the story. In contrast, the story list should scroll smoothly both for its contents (when you use the keyboard shortcuts to select the next item in the list) and when it becomes the primary view on mobile (say, if you reach the end of all unread stories).
Ultimately, the solution was to split scrolling into separate code paths, depending on whether we want to move between columns, or within them. The code still uses scrollIntoView for panel transitions, and modules send a request over the global event bus if they want a different view to take over. The panels themselves are shell custom elements that offer individual control for scrolling content separately from the main viewport — the reader and story list dispatch DOM events up the tree to the ancestor panel when they need their column to scroll vertically to a certain element or offset, with or without an animated transition.
Promises, promises
At the start of the process, I didn't intend to do anything to the server side of Weir. It had already been built to handle cross-domain requests, so I didn't need to change anything for local development, and while it has its quirks, I'm generally pretty happy with how it works. Then I hit a snag: the "mark all as read" API route returns a count of stories that were updated, but not the new unread/total story counts. It was just irritating enough that I decided to dig in and make one little change. Of course it snowballed from there.
Since it was as much a learning experience as it was a legit project, Weir doesn't use a typical Node library for setting up its API. I wrote my own request handler and router on top of the basic HTTP module. That part of the code has actually aged pretty well. However, to manage the async chains involved in making database calls and RSS fetches, I wrote a utility library called Manos (because you're putting your code in the hands of fate), and that stuff was a mess.
These days, the ideal way to handle async flow is with the await keyword, so you don't have to write code out of order or in a snarl of function wrappers. But using await requires functions to return promises instead of accepting callbacks, and all of my code was written before JavaScript promises were standardized. So to make it a little easier to insert a db.getStatus() call in a single handler, I ended up converting the whole application to a promise-based flow.
Luckily, I went through a similar process a few years back with Caret, when async/await shipped in Chrome, so I largely knew what to expect. Surprisingly, the biggest change is not in the routes at all, but in the "Hound" component that periodically fetches feed items from various URLs: subscriptions have to be grouped into batches, then each batch is requested, sometimes decompressed from gzip, fed to a streaming parser, and finally saved to the database. As implemented with Manos, the code was at best out of order, and at worst involved a lot of "clever" functional tricks.
The new Hound flow has its issues — I think there's some leftover weirdness from the way old-school Node streams interact with each other that requires pausing the request as soon as it comes in — but it now reads top to bottom, and most of the complication comes from the problem domain and not the language. At some point, updating the request code to use something like fetch() will probably eliminate most of the remaining issues.
Second-system syndrome
There's a truism in development circles that a rewrite is often a debacle — people point to the rewrite of Netscape 4.0 that's blamed for tanking the company, or the Copland OS at Apple. My personal suspicion is that this is survivorship bias: Netscape itself was a from-scratch rewrite originally from the Mosaic browser, and while Copland was not a success, current Mac OS is built on the bones of NeXT, itself a from-scratch OS.
In any case, most people aren't building browsers or operating systems. For these kinds of small projects, I think there's value in taking another run at an idea, armed with knowledge about what worked or didn't work the first time around. In fact, that might be the best argument for these kinds of small projects (API clients, media players, browser extensions): they're a chance to stop, try something different, and measure our skills against our past selves. I learn a lot from these little rewrites, and I think it's safe to say that I am better at this than I was eight years ago.
I still wish they'd just bring back Reader, though.
October 2, 2018
Generators: the best JS feature you're not using
People love to talk about "beautiful" code. There was a book written about it! And I think it's mostly crap. The vast majority of programming is not beautiful. It's plumbing: moving values from one place to another in response to button presses. I love indoor plumbing, but I don't particularly want to frame it and hang it in my living room.
That's not to say, though, that there isn't pleasant code, or that we can't make the plumbing as nice as possible. A program is, in many ways, a diagram for a machine that is also the machine itself — when we talk about "clean" or "elegant" code, we mean cases where those two things dovetail neatly, as if you sketched an idea and it just happened to do the work as a side effect.
In the last couple of years, JavaScript updates have given us a lot of new tools for writing code that's more expressive. Some of these have seen wide adoption (arrow functions, template strings), and deservedly so. But if you ask me, one of the most elegant and interesting new features is generators, and they've seen little to no adoption. They're the best JavaScript syntax that you're not using.
To see why generators are neat, we need to know about iterators, which were added to the
language in pieces over the years. An iterator is an object with a next() method,
which you can call to get a new result with either a value or a "done" flag. Initially, this
seems like a fairly silly convention — who wants to manually call a loop function over
and over, unwrapping its values each time? — but the goal is actually to enable new
syntax once the convention is in place. In this case, we get the generic for ...
of loop, which hides all the next() and result.done checks
behind a familiar-looking construct:
for (var item of iterator) {
// item comes from iterator and
// loops until the "done" flag is set
}
Designing iteration as a protocol of specific method/property names, similar to the way that Promises are signaled via the then() method, is something that's been used in languages like Python and Lua in the past. In fact, the new loop works very similarly to Python's iteration protocol, especially with the role of generators: while for ... of makes consuming iterators easier, generators make it easier to create them.
You create a generator by adding a * after the function keyword. Within the
generator, you can ouput a value using the yield keyword. This is kind of like a
return, but instead of exiting the function, it pauses it and allows it to resume
the next time it's called. This is easier to understand with an example than it is in text:
function* range(from, to) {
while (from <= to) {
yield from;
from += 1;
}
}
for (var num of range(3, 6)) {
// logs 3, 4, 5, 6
console.log(num);
}
Behind the scenes, the generator will create a function that, when called, produces an iterator. When the function reaches its end, it'll be "done" for the purposes of looping, but internally it can yield as many values as you want. The for ... of syntax will take care of calling next() for you, and the function starts up from where it was paused from the last yield.
Previously, in JavaScript, if we created a new collection object (like jQuery or D3 selections), we would probably have to add a method on it for doing iteration, like collection.forEach(). This new syntax means that instead of every collection creating its own looping method (that can't be interrupted and requires a new function scope), there's a standard construct that everyone can use. More importantly, you can use it to loop over abstract things that weren't previously loopable.
For example, let's take a problem that many data journalists deal with regularly: CSV. In
order to read a CSV, you probably need to get a file line by line. It's possible to split
the file and create a new array of strings, but what if we could just lazily request the
lines in a loop?
function* readLines(str) {
var buffer = "";
for (var c of str) {
if (c == "\n") {
yield buffer;
buffer = "";
} else {
buffer += c;
}
}
}
Reading input this way is much easier on memory, and it's much more expressive to think
about looping through lines directly versus creating an array of strings. But what's really
neat is that it also becomes composable. Let's say I wanted to read every other line from
the first five lines (this is a weird use case, but go with it). I might write the
following:
function* take(x, list) {
var i = 0;
for (var item of list) {
if (i == x) return;
yield item;
i++;
}
}
function* everyOther(list) {
var other = true;
for (var item of list) {
if (!other) continue;
other = !other;
yield item;
}
}
// get my weird subset
var lines = readLines(file);
var firstFive = take(5, lines);
var alternating = everyOther(firstFive);
for (var value of alternating) {
// ...
}
Not only are these generators chained, they're also lazy: until I hit my loop, they do no work, and they'll only read as much as they need to (in this case, only the first five lines are read). To me, this makes generators a really nice way to write library code, and it's surprising that it's seen so little uptake in the community (especially compared to streams, which they largely supplant).
So much of programming is just looping in different forms: processing delimited data line by line, shading polygons by pixel fragment, updating sets of HTML elements. But by baking fundamental tools for creating easy loops into the language, it's now easier to create pipelines of transformations that build on each other. It may still be plumbing, but you shouldn't have to think about it much — and that's as close to beautiful as most code needs to be.
April 15, 2016
Calculated Amalgamation
In a fit of nostalgia, I've been trying to get my hands on a TI-82 calculator for a few weeks now. TI BASIC was probably the first programming language in which I actually wrote significant amounts of code: although a few years later I'd start working in C for PalmOS and Windows CE, I have a lot of memories of trying to squeeze programs for speed and size during slow class periods. While I keep checking Goodwill for spares, there are plenty of TI calculator emulation apps, so I grabbed one and loaded up a TI-82 ROM to see what I've retained.
Actually, TI BASIC is really weird. Things I had forgotten:
- You can type in all-caps text if you want, but most of the time you don't, because all of the programming keywords (If, Else, While, etc.) are actually single "character" glyphs that you insert from a menu.
- In fact, pretty much the only code that's typed manually are variable names, of which you get 26 (one for each letter). There are also six arrays (max length 99), five two-dimensional matrices (limited by memory), and a handful of state variables you can abuse if you really need more. Everything is global.
- Variables aren't stored using =, which is reserved for testing, but with a left-to-right arrow operator: value → dest I imagine this clears up a lot of ambiguity in the parser.
- Of course, if you're processing data linearly, you can do a lot without explicit variables, because the result of any statement gets stored in Ans. So you can chain a lot of operations together as long as you just keep operating on the output of the previous line.
- There's no debugger, but you can hit the On key to break at any time, and either quit or jump to the current line.
- You can call other programs and they do return after calling, but there are no function definitions or return values other than Ans (remember, everything is global). There is GOTO, but it apparently causes memory leaks when used (thanks, Dijkstra!).
I'd romanticized it over time — the self-contained hardware, the variable-juggling, the 1-bit graphics on a 96x64 screen. Even today, I'm kind of bizarrely fascinated by this environment, which feels like the world's most cumbersome register VM. But loading up the emulator, it's obvious why I never actually finished any of my projects: TI BASIC is legitimately a terrible way to work.
In retrospect, it's obviously a scripting language for a plotting library, and not the game development environment I wanted it to be when I was trying to build Wolf3D clones. You're supposed to write simple macros in TI BASIC, not full-sized applications. But as a bored kid, it was a great playground, and the limitations of the platform (including its molasses-slow interpreter) made simple problems into brainteasers (it's almost literally the challenge behind TIS-100).
These days, the kids have it way better than I did. A micro:bit is cheaper and syncs with a phone or computer. A Raspberry Pi is a real computer of its own, as is the average smartphone. And a laptop or Chromebook with a browser is miles more productive than a TI-82 could ever be. On the other hand, they probably can't sneak any of those into their trig classes and get away with it. And maybe that's for the best — look how I turned out!
November 20, 2015
Weir, year two
I realized the other day that Google Reader shut down in June of 2013, which means I've been using Weir as my RSS reader for more than two years now. It's my longest-running software project, and still one of the most complex things I've built in Node. And apart from occasional revisions, it's been up and running constantly, in mobile and desktop browsers, that entire time.
I don't log out a lot of metrics from Weir, so there's a lot of stuff that I'm not tracking. But I can say that there are currently 113 subscriptions, with around 6,000 stories in the database. The server that hosts the app (as well as my various domains) downloads about 20GB of data each month, most of which is probably Weir (the rest is e-mail and server updates, and I'm frankly not that popular). It also hovers around 10% of available memory, which is pretty good for a garbage-collected language on a piddly little VM.
On the client side of things, the Angular code has definitely started to show its age. This was the project that I used to learn Angular, and since then I've learned a lot about the framework. Would I use it if I were writing Weir from scratch? I'm not sure. I still love the databinding aspect of Angular, but I suspect I could write a smaller, nimbler version of the UI in vanilla JavaScript pretty easily. At some point, I may give it a shot: the server API is clean enough that writing a new client should be relatively straightforward.
As an experiment in self-hosting a cloud service, Weir is a mixed success. But I have grown to love the way that something I wrote has become a fixture of my life. I clear out my stream on the bus in the morning. Throughout the day, Weir's purple tab icon lights up to let me know that new items are available. It feels like wearing clothes that I tailored for myself — using it feels a little nicer than it should, just from the pride in its construction.
February 27, 2014
Just Use Ed
There's a regular, recurring movement to replace text-based programming with some kind of graphical version. These range from Scratch (offering "blocks" to make text syntax more friendly) to Pure Data (node-based dataflow programming). Rarely do any of them take off (Scratch and pd are successful within education and audio, respectively, but little-used elsewhere), but that doesn't stop anyone from trying.
It may be the fact that I started as a writer, or that I was a language nut in college, but I've always felt that text-based programming doesn't get a lot of respect. The written word is one of the great advances of civilization. You can pack a lot of meaning into a line of text, and code is no different. Good source code can range from whimsical to workmanlike, a gamut that's hard to imagine existing in the nest of wiring that is the graphical languages.
As a result, text editing is important to me. It's important to a lot of people, but most of them don't write an editor, and I ended up doing that. I figured I'd write up some notes on the different ways people have written their editors, and why I picked one model in particular for Caret. It may be news to many people that there are even multiple models to consider, but that's programming for you: there's at least four ways to put letters into a document, and bitter wars between factions for each of them.
The weirdest editor still in common usage, of course, is Vim. Born from the days when network connections were too slow to actually update text in realtime, Vim uses a shorthand language for text editing. You don't hold delete until some amount of text is gone in Vim — instead, you type "d2w", meaning "delete two words." You also can't type directly until you switch into the "insert" mode with the "i" or "a" commands. Like many abusive subcultures, people who learn this shorthand will swear up and down that it's the only way to work, even though it's clearly a relic of a savage, bygone age.
(Vim and Emacs are often mentioned in comparison to each other, because they tend to be used by very similar kinds of people who, nevertheless, insist that they're very different. I don't really know very much about Emacs, other than it's written in Lisp and it's not as eyeball-rolling weird as Vim, so I'm ignoring it for the purposes of this discussion.)
Acme tends to look a little more traditional, but it is actually (I think) more radical than Vim, because it redefines the relationship between interface and editor. Acme turns all documents into hypertext: middle clicking a filename opens that file, and clicking a word (like "copy" or "paste") actually runs that command (either in a shell, or in Acme). There's no fixed interface in Acme, just a set of menu bars that are also text fields. I love the elegance of this idea, where a person builds an text editor's UI just by... editing text.
Which brings us to Sublime. I've been very clear that Caret is modeled closely on Sublime, with a few changes to account for quirks of the platform and my own preferences. That's partly because it's generally considered the tool of choice for web developers, and partly because it's genuinely the editor that has my favorite workflow tools. Insofar as Sublime has a philosophy, it is to prioritize clarity and transparency over power. That's not to say it's not powerful — it certainly is. But it tries to be obvious in a way that other editors do not.
For example, say you need to change a variable name throughout a function. Instead of immediately writing a regex or a macro, Sublime lets you select all the instances of that variable with the mouse or keyboard, which creates multiple cursors. Then you just type the new name. It's not as powerful as a regular expression, but 90% of the time, it's probably what you wanted to do anyway. Sublime's command/go-to palette is another smart-but-obvious idea: instead of hunting through the menu or the filesystem, open the palette and type to fuzzy-filter the list. It's the speed of a command line without the hostility.
To paraphrase an old saw, the best feature is the one you have with you. That's why putting the command palette in Caret was a must, since it puts all the menu items just a few keystrokes away. Even now, I don't always remember where a given menu item is in the toolbar in my own editor, because I hardly ever use the mouse. There was a good week when menus looked completely wrong, and I never even noticed.
The reason I've started looking over other editors now is that I think Caret can reach for more than just parity with Sublime. I'm intrigued by the ways that Acme makes it easy to jump around files, and lately I've been thinking about what it means to be an editor built in "web technology." Adding the ability to open links from a URL is a given, but it's only the start: given that OAuth provides a simple, standard method of authenticating against a remote server, a File implementation for Caret could easily open files against service endpoints for something like Github or Ghost in a generic way. It would be a universal cloud editor, but easily capable of running locally.
Of course, Caret won't be the last editor to try something different (just this week, Github announced their own effort), but it's still pretty amazing how many ways we have to solve a simple problem like "typing letters into a file." As a writer and a coder, I love being spoiled for choice.
November 22, 2013
Plug In, Turn On, Drop Out
This is me, thinking about plugins for Caret, as I find myself doing these days. In theory, extensibility is my focus for the next major release, because I think it's a big deal and a natural next step for a code editor. In practice, it's not that simple.
Approach #1: Postal Services
Chrome has a pretty tight security model applied to packaged apps, not the least of which is a strict content security policy. You can't run code from outside your application. You can't construct code using eval (that's good!) or new Function (that's bad). You can't add new files to your application (mostly).
Chrome does expose an inter-app messaging system similar to postMessage, and I initially thought about using this to create a series of hooks that external applications could use. Caret would broadcast notifications to registered listeners when it did something, and those listeners could respond. They could also trigger Caret commands via message (I do still plan to add this, it's too handy not to have).
Writing plugins this way is neatly encapsulated and secure, but it's also going to be intensely frustrating. It would require auditing much of Caret's code to make sure that it's all okay with asynchronous operation, which is not usually the case right now. I'd have to make sure that Caret is sufficiently chatty, because we'd need hooks everywhere, which would clutter the code with broadcast/response blocks. And it would probably mean writing a helper app to serve as a patchboard between applications, and as a debugging tool.
I'm not wild about this one.
Approach #2: Repo, Man
I've been trying to think of a way around the whole inter-app messaging paradigm for about a month now. At the same time, I've been responding to requests for Git and remote filesystem support, which will not be a core Caret feature. For some reason, thinking about the two in close proximity started me thinking along a new track: what if there were a way to work around the security policy using the HTML5 file system? I decided to run some tests.
It turns out this is absolutely possible: Chrome apps can download a script from any server that's whitelisted in their manifest, write that out to the filesystem, and then get a special URL to load that file into a <script> tag. I assume this has survived security audits because it involves jumping through too many hoops to be anything other than deliberate.
The advantages of this approach are numerous. Plugin code would operate directly alongside of Caret's source, able to access the same functions and modules and call the same APIs that I use. It would be powerful, and would not require users to publish plugins to the Chrome store as if they were full applications. And it would scale well--all I would need to do is maintain the index and provide some helper functions for developers to use when downloading and caching their code.
Unfortunately, it is also apparently forbidden by the Chrome Web Store policies, which state:
Packaged apps should not ... Download or execute scripts dynamically outside a sandboxed environment such as a webview or a sandboxed iframe.At that point, we're back to postMessage unless I want to be banned from the store. So much for the workaround.
Approach #3: Local hosting
So how can I make plugins work for end users? Well, honestly, maybe I don't. One of the nice things about writing developer tools, particularly oddball developer tools, is that the people using them and wanting to expand on them are expected to have some degree of technical knowledge. They can be trusted to figure out processes that wouldn't necessarily be acceptable for average computer users. In this case, that might mean running Caret as an unpacked app.
Loading Caret from source is not difficult--I do it all the time while I'm testing. Right now, if someone wants to fork Caret and add their own features, that's easy enough to do (and actually, a couple of people have done so already). What it lacks is a simple entry point for people who want to contribute functionality without digging into all the modules I've already written.
By setting up a plugins directory and a little bit of infrastructure, it's possible to reach a middle ground. Developers who really want extra packages can load Caret from source, dump their code into a designated location, and have their code bootstrapped automatically. It's not as friendly as having web store distribution, and it's not as elegant as allowing for a central repo, but it does deliver power without requiring major rewrites.
Working through all these different approaches has given me a new appreciation for insecurity, which sounds funny but it's true. Obviously I'm in favor of secure computing, but working with mobile operating systems and Chrome OS that strongly sandbox their code tends to make a person aware of how helpful a few security holes can be, and vice versa: the same points for easy extension and flexibility are also weak points that can be exploited by an attacker. At times like this, even though I should maybe know better, that tradeoff seems absolutely worth it.
November 14, 2013
For Free Ninety Nine I'll Beat 99 Acts Down
Assuming that the hamster powering the Chrome web store stats is just resting, Caret clicked over to 10,000 installations sometime on Monday. That's a lot of downloads. At a buck a piece, even if only a fraction of those people had bought a for-pay version, that might be a lot of money. So why is Caret free? More importantly, why is it free and open source? Ultimately, there are three reasons:
- I feel like I owe the open source community for the value I've gotten from it (basically, everything on the Internet), and this is a way to repay that debt.
- Caret isn't really just mine. It's heavily influenced by Sublime, and builds on another open source project for its text processing. As such, it feels awkward to charge money for other peoples' work, even if Caret's unique code is significant in its own right.
- I think I get more value (i.e. job marketability, reputation, skill practice) out of being the person with a chart-topping Chrome app, in the long term, than I would get from sales.
Originally, I had planned on writing about how I reconcile being a passionate supporter of paid writing while giving away my hobby code, but I don't actually see any conflict. I expect a paycheck for freelance coding the same way I expect it for journalism — writing here (and coding Caret) doesn't directly benefit anyone but me, and it doesn't really cost me anything.
In fact, it turns out that both industries also share some uncomfortable habits when it comes to labor. Ashe Dryden writes:
Statistically, we expect that the demographic breakdown of people contributing to OSS would be about the same as the people who are participating in the OSS community, but we aren't seeing that. Ethnicity of computing and the US population breaks down what we would hope to see as far as ethnicity goes. As far as gender, women make up 24% of the industry, according to the same paper that gave us the 1.5% OSS contributor statistic.
Dryden was responding to a sentiment that I've seen myself (and even been guilty of, from time to time): using a person's open source record on sites like GitHub as a proxy for hireability. As she points out, however, building an open source portfolio is something that's a lot easier for white men. We're more likely to have free time, more often have jobs that will pay for open source contributions, and far less likely to be harassed or dismissed. I was aware of those factors, but I was still shocked to see that diversity numbers in open source are so low. We need to do better.
As eye-opening as that is, I think Dryden's middle section centers around a really interesting question: who profits?
I'd argue that the people who benefit the most from the unpaid labor of OSS as well as the underpaid labor of marginalized people in technology are business owners and stakeholders in these companies. Having to pay additional hundreds of thousands or millions of dollars for this labor would mean smaller profit margins. Technology is one of the most profitable industries in the US and certainly could support at least pay equality, especially considering how low our current participation is from marginalized people.Her conclusion — that the community benefits, but it's mostly businesses who boost their profits from free software — should be unsettling for anyone who contributes to open source, and particularly those of us who see it as a way to spread a little socialist good will. For this reason, if nothing else, I'll always prefer the GPL and other "copyleft" licenses, forcing businesses to play ball if they want to use my code....Open source originally broke us free from the shackles of proprietary software which forced us to "pay to play" and gave us little in the way of choices for customization. Without realizing it, we've ended up in a similar scenario where we are now paying for the development of software that large companies financially benefit from with little cost to them.
May 30, 2013
Project Seymour
A month from now, Google will shut down Reader, leaving RSS addicts in the lurch. I suspect this will be both more and less disruptive than anticipated: expect replacement services to go through another set of growing pains, but RSS isn't exactly a high lock-in situation, and most people will find a new status quo fairly quickly.
I am not eager to move from one hosted service to another (once burned, twice shy), nor do I want to go back to native applications that can't share progress, so as soon as the shutdown was announced I started working on a self-hosted RSS reader. I applied the same techniques I'd used for Big Fish Unlimited: an easy-to-configure router, a series of views talking to the database only through model classes, and heavy use of closures for dependency management and callbacks. I built a wrapper around PHP's dismal cURL library. It was a nice piece of architecture.
It also bogged down very, very quickly. My goal was a single-page application with straightforward database queries, but I was building the foundation for a sprawling, multi-page site. Any time I started to dip in and add functionality, I found myself frustrated by how much plumbing I needed in order to do it "the right way." I was also annoyed by the difficulty of safely requesting a large number of feeds in parallel in PHP. The language just isn't built for that kind of task, even with the adaptations and improvements that have been pasted on.
This week I decided to start over, this time using Node.js and adopting a strict worse is better philosophy. When I use Reader, 99% of my time is spent in "All Items" pressing the spacebar (or, on mobile, clicking "Mark Items as Read") to advance the stream. So I made that functionality my primary concern, and wrote only as much as I needed to (both in terms of code size and elegance) to make that happen. In two days, I've gotten farther than I had with the PHP, and I'm much happier with the underlying platform as well--Node is unsurprisingly well suited to firing off tens and hundreds of concurrent requests.
I've just posted the work-in-progress code for the application, which I'm calling Weir (just barely winning out over "Audrey II"), to a public GitHub repo. It is currently ugly, badly-documented, and patchy in places. The Angular code I'm using for the front-end is obviously written by a someone with very little experience using the library. There's lots of room for improvement. On the other hand, my momentum is very good. By next week, I expect Weir will be good enough for me to dogfood it full time, and at that point improvements will come naturally whenever I need to smooth out the rough edges.
I like this way of working--"worse is better"--quite a bit. It's not always pretty, but it seems effective so far. It also fits in well with my general coding style, which is (perhaps unsurprisingly) on the left-ish side of Steve Yegge's developer politics. I like elegance and architecture as much as the next person, but when it all comes down to it, there's no point in elegant code that never gets used.
Writing my own Reader alternative is also proving educational. The conventional wisdom is that RSS readers benefit greatly from running at scale: operations like feed retrieval can be performed once for all subscribers, spreading the costs out. The flip side is that you're at the mercy of the server bot for when you get updates. High-frequency feeds, such as politics or news, get batched up instead of coming in as they're posted. I'm also able to get a lot more feedback on which feeds are dead, which came as a surprise: Reader just swallowed the errors whole. All in all, I doubt the experience will be any worse.
Currently, Weir isn't much good for public consumption. I've made a sanitized copy of my config file in the repo, but there's no setup script for the database, and no import step for getting your subscriptions loaded up. I hope to have that ready soon, and the code is licensed under the GPL, so pull requests and feature suggestions are welcomed as it becomes usable for other people.
